最近,DeepSeek 爆火,其先进的算法和卓越的能力,凭一己之力推动国内 AI 大模型跨越式发展。但使用 DeepSeek 时,经常出现服务器繁忙的情况,将其部署在本地电脑就方便很多。那么如何将DeepSeek部署到本地电脑呢?本文将介绍DeepSeek本地部署教程。
一、借助 Ollama 部署
(一)下载安装 Ollama
部署 DeepSeek 要用到 Ollama,它支持多种大模型,其官网为ollama.com ,macOS、Linux 和 Windows 系统都可下载安装。以 Windows 系统为例,进入官网后,根据系统提示下载对应的安装包,下载完成后运行安装程序,按照安装向导的提示完成安装。
(二)下载 DeepSeek-R1
进入 Ollama 官网,找到 “Models”。

进入后即可看到 deepseek - r1 模型,如果没有,在搜索栏搜索即可。
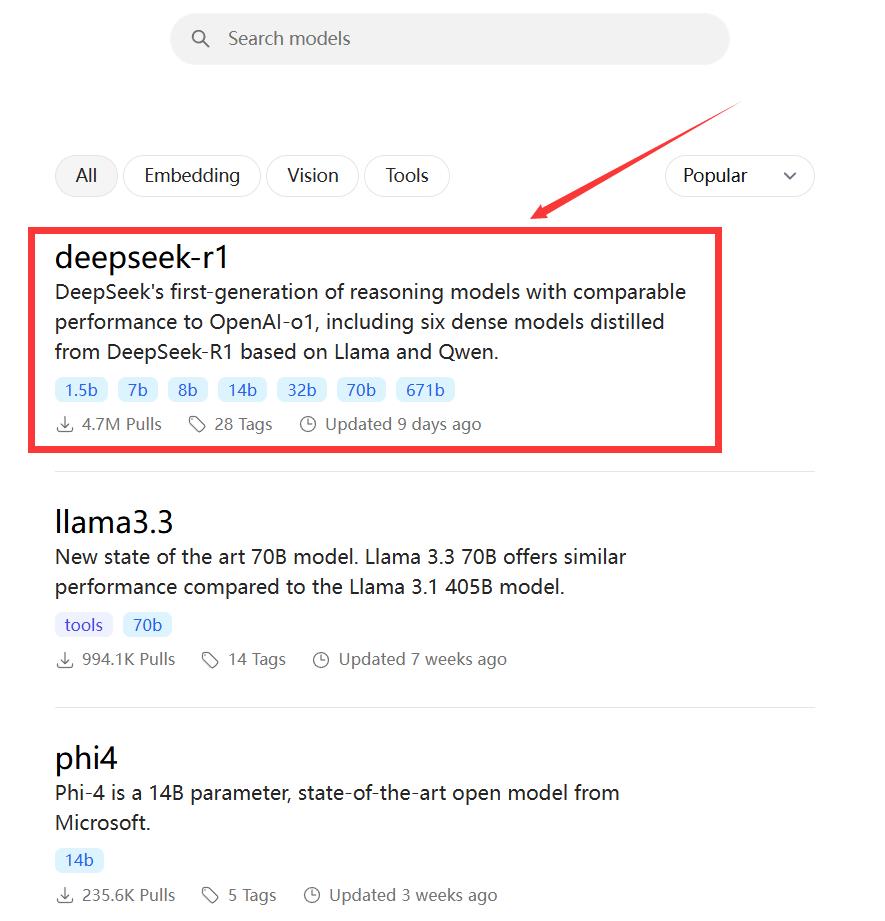
这里有很多版本可选,如 1.5b、7b、8b、14b、32b、70b 或 671b 等 。模型越大,要求电脑内存、显卡等的配置越高。例如,1.5B 适合体验 / 尝鲜的场景,只有大约 3GB 的文件;7B 适合普通内容创作及开发测试场景,文件提升至 8GB,推荐 16GB 内存 + 8GB 显存;8B 在 7B 的基础上更精细一些,适合对内容要求更高更精的场景,同样适合大多数用户;14B 则提升至 16GB,建议 12 核 CPU + 32GB 内存 + 16GB 显存,适合专业及深度内容创作场景。大家可以根据自己的配置和需求选择参数规模。
找到 Windows【开始菜单】,鼠标右键点击【终端管理员】。
复制对应版本的下载代码(如 8b 的代码)。
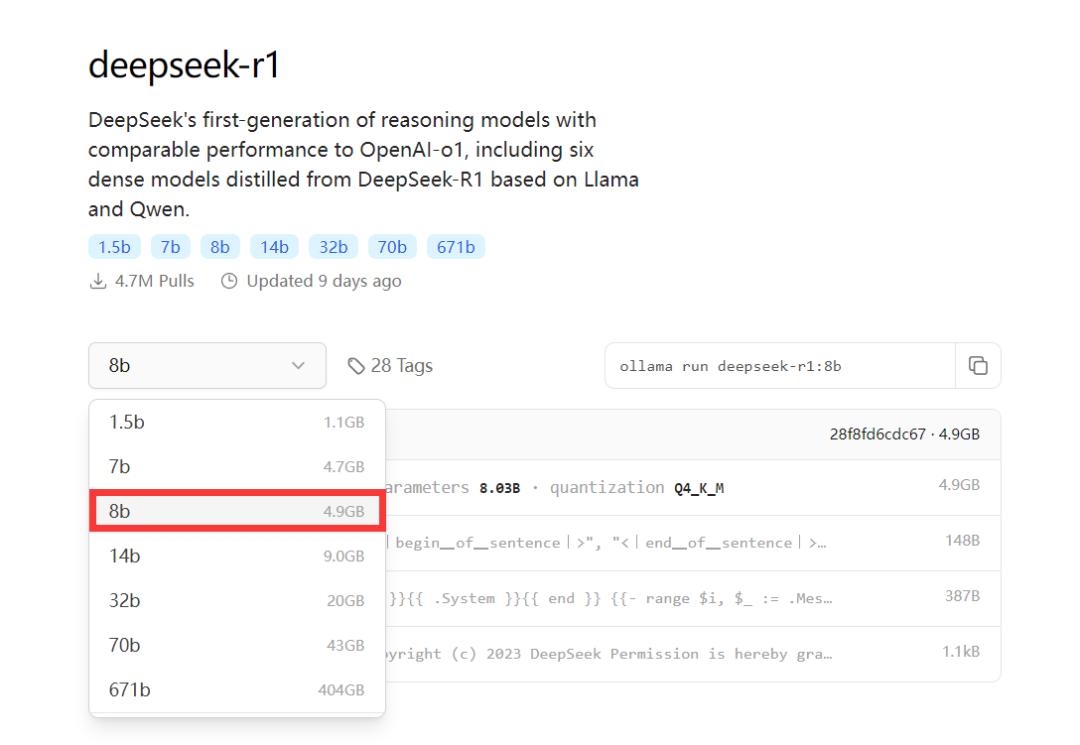
粘贴到 PowerShell (管理员) 运行框,然后回车。出现下载等待窗口,等待下载完成。
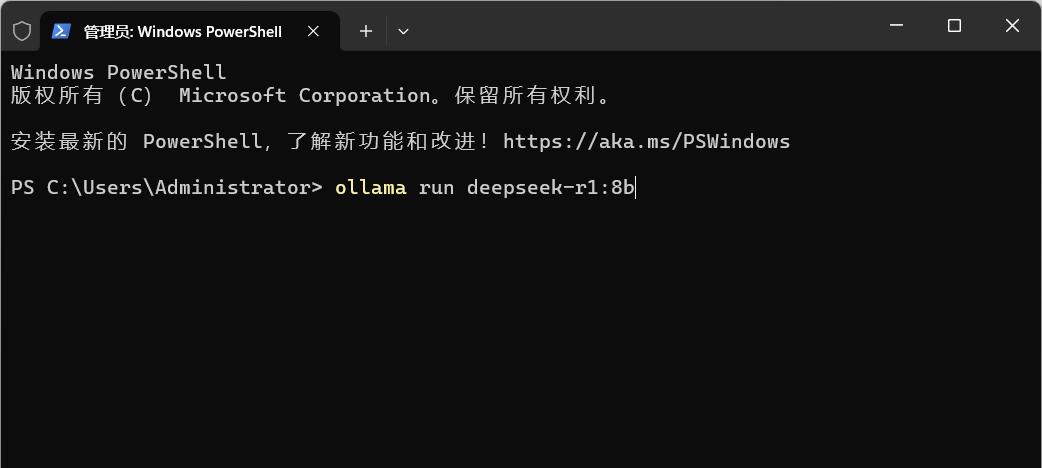
下载完成后稍微等待,看到 “success”,即部署完成。
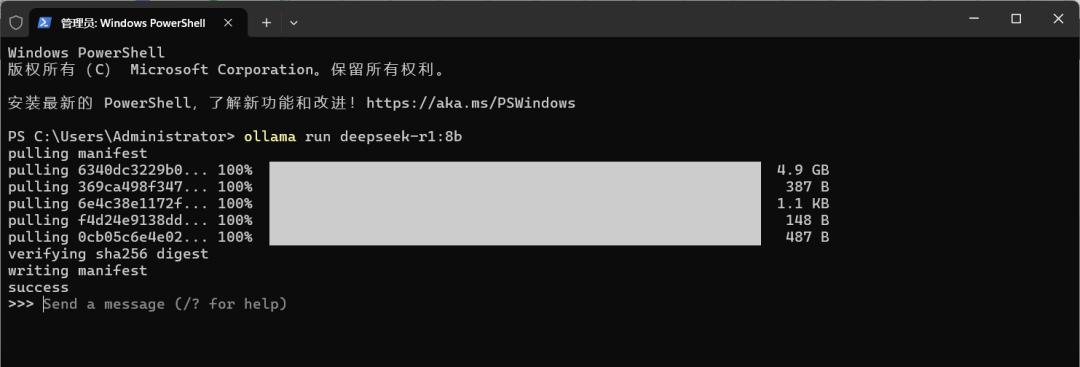
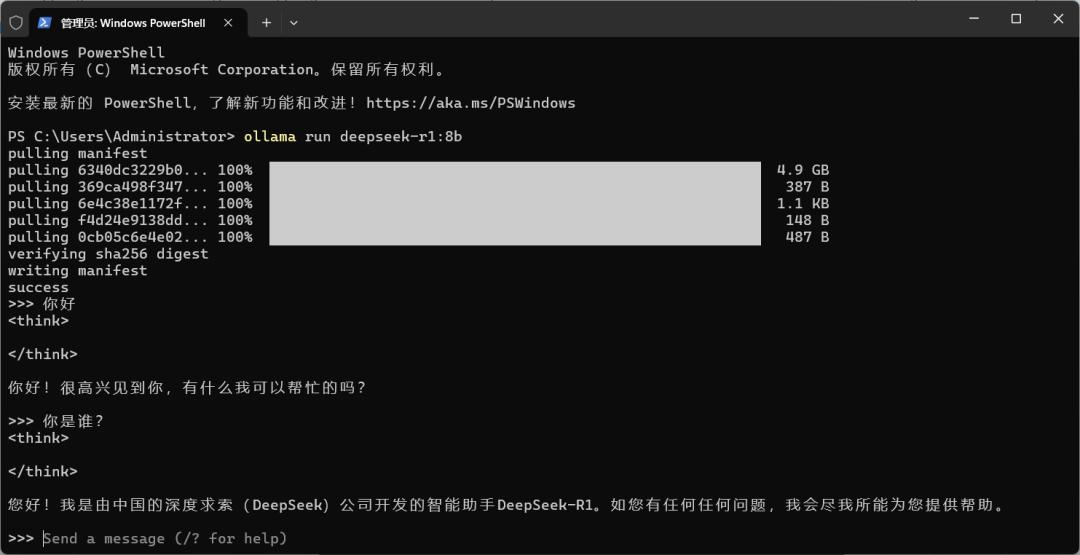
部署完成,可 “send a message”,输入内容即可开始对话。
(三)Chatbox 前端搭建
通过上述操作,虽已部署好 DeepSeek,但每次使用都要在终端管理员里操作,较为繁琐。这里可以借助 Chatbox,实现网页或客户端操作。
下载安装 Chatbox,其官网为 chatboxai.app/zh ,进入官网下载安装 Chatbox 客户端。

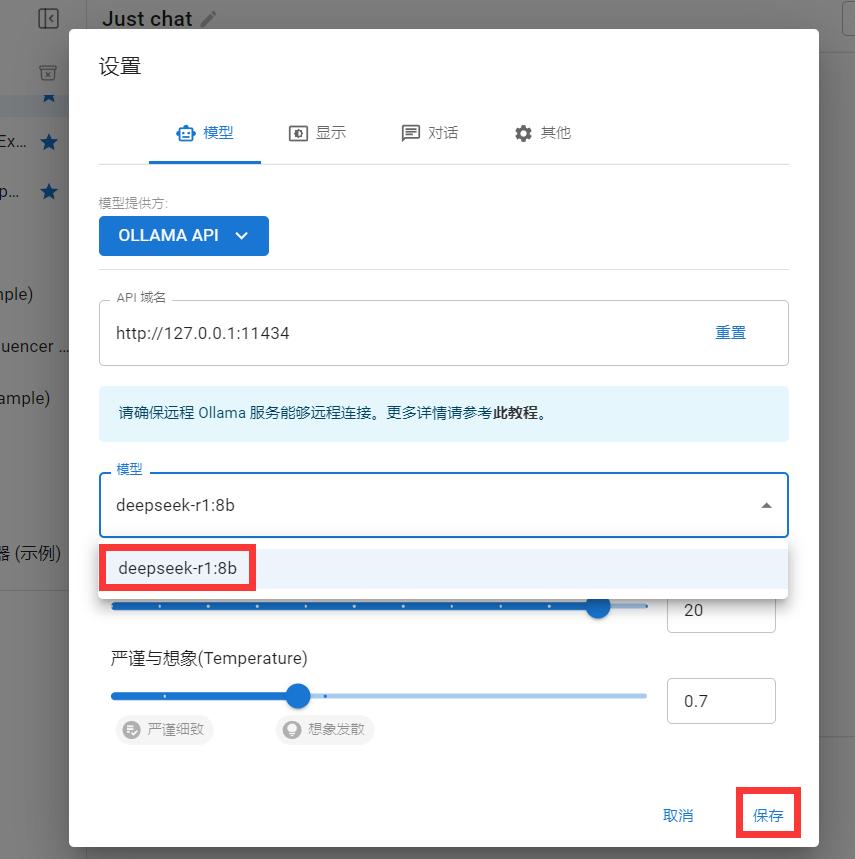
点击设置,选择 Ollama API。
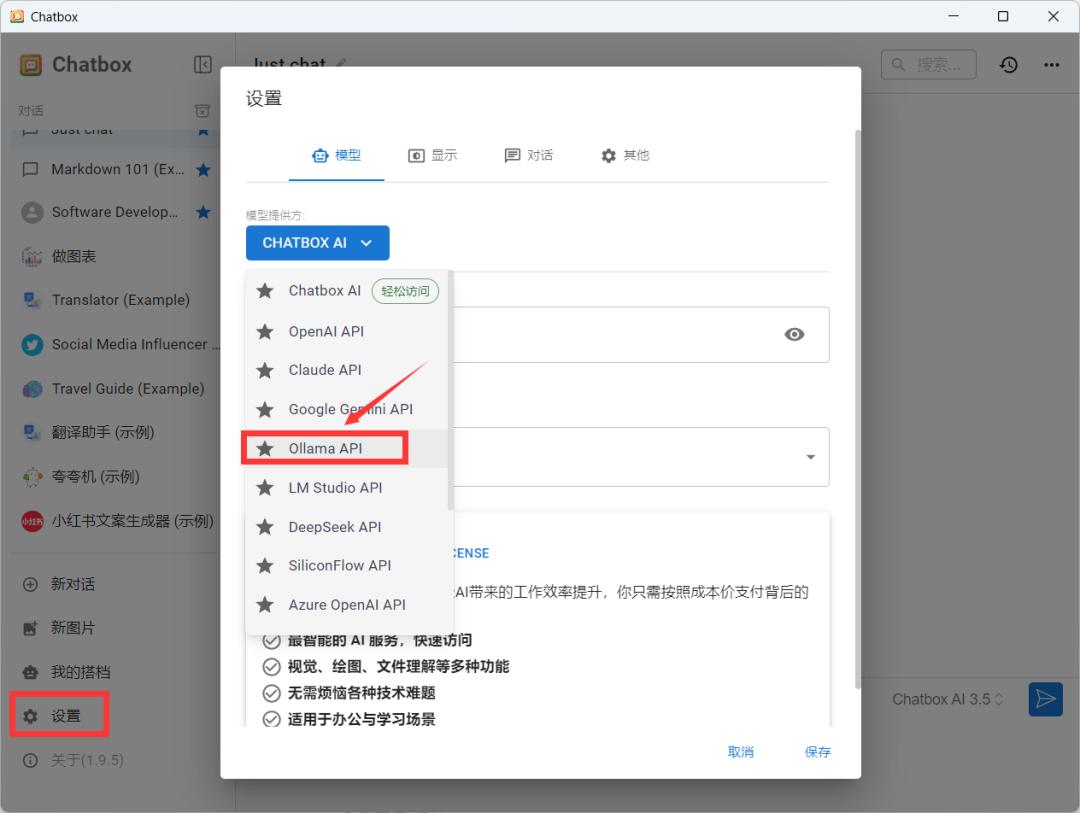
选择安装好的 deepseek r1 模型,保存即可。
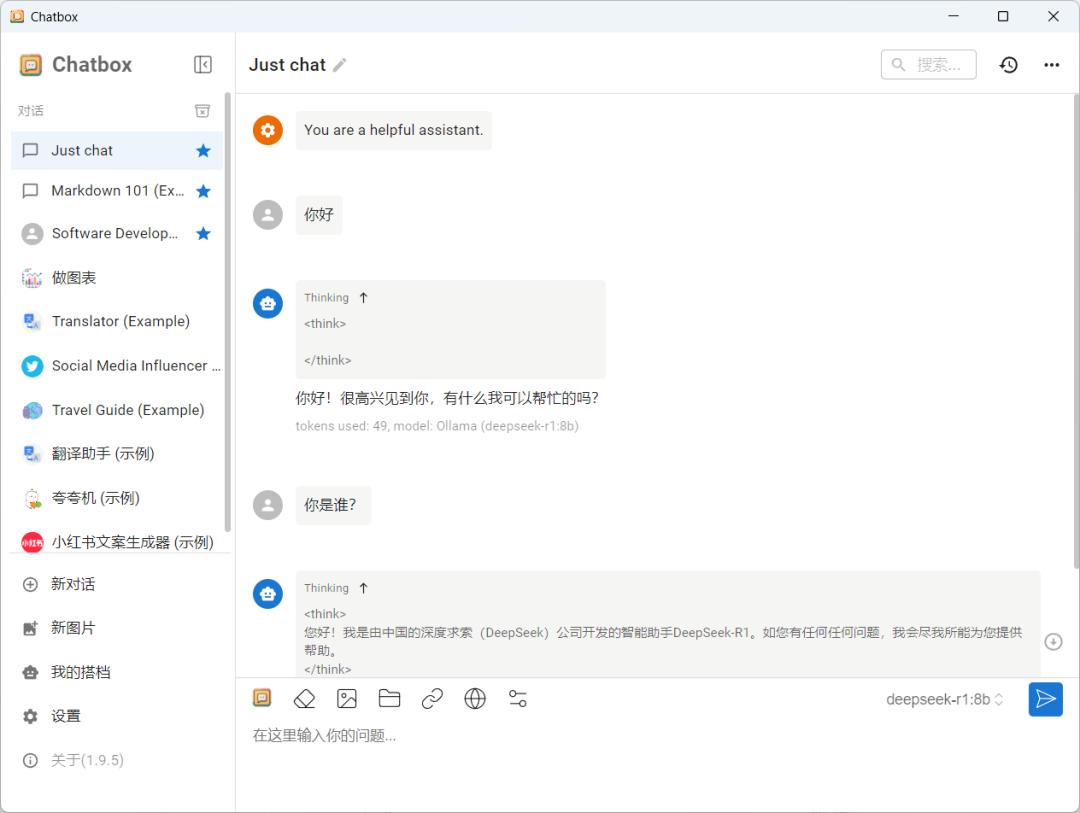
至此部署完成,就可以正常使用了。
二、借助 LM Studio 部署
(一)确认硬件要求
在开始部署之前,先确保设备满足以下硬件要求:显卡 GTX 1060 (6GB) 及以上,推荐 RTX3060 及以上;内存容量 8GB,推荐 16GB 及更高;存储空间 C 盘剩余 20GB,推荐使用 NVMe 固态硬盘。
(二)安装 LMStudio 客户端
在官网 lmstudio.ai 下载对应操作系统的安装包,随后双击运行并按照提示完成安装。安装完成后启动 LM Studio,进入用户界面。
(三)加载模型
进入 LM Studio 之后先点击右下角的设置图标 (小齿轮) 将语言改为简体中文,然后就可以加载模型。
加载模型有两种情况:
若能自行找到各种不同版本的模型,那就下载到本地,然后点击左上方文件夹的图标,选择模型目录导入即可,优点是可以选择自定义的模型,而且下载速度有保障。
若不会自己找模型,就在 LMStudio 的设置里,常规部分选中 “Use LM Studio's Hugging Face” 的复选框,然后点击左上方的搜索图标 (放大镜),搜索 deepseek 即可找到各种不同版本的模型,优点是使用简单,但是下载非常不稳定。
(四)开始使用
部署完成之后,点击 LMStudio 左上方的对话框,然后在顶部选择要加载的模型即可。开始前可以先在顶部的模型这里设置上下文长度和 GPU 负载等,模型加载完成之后就可以开始使用。对于有更高要求的用户,LMStudio 中支持创建多个文件夹,分类存放不同用途的模型,方便快速切换,LM Studio 还支持通过本地 API 接口与其他应用程序集成,实现更复杂的 AI 应用。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






